
People
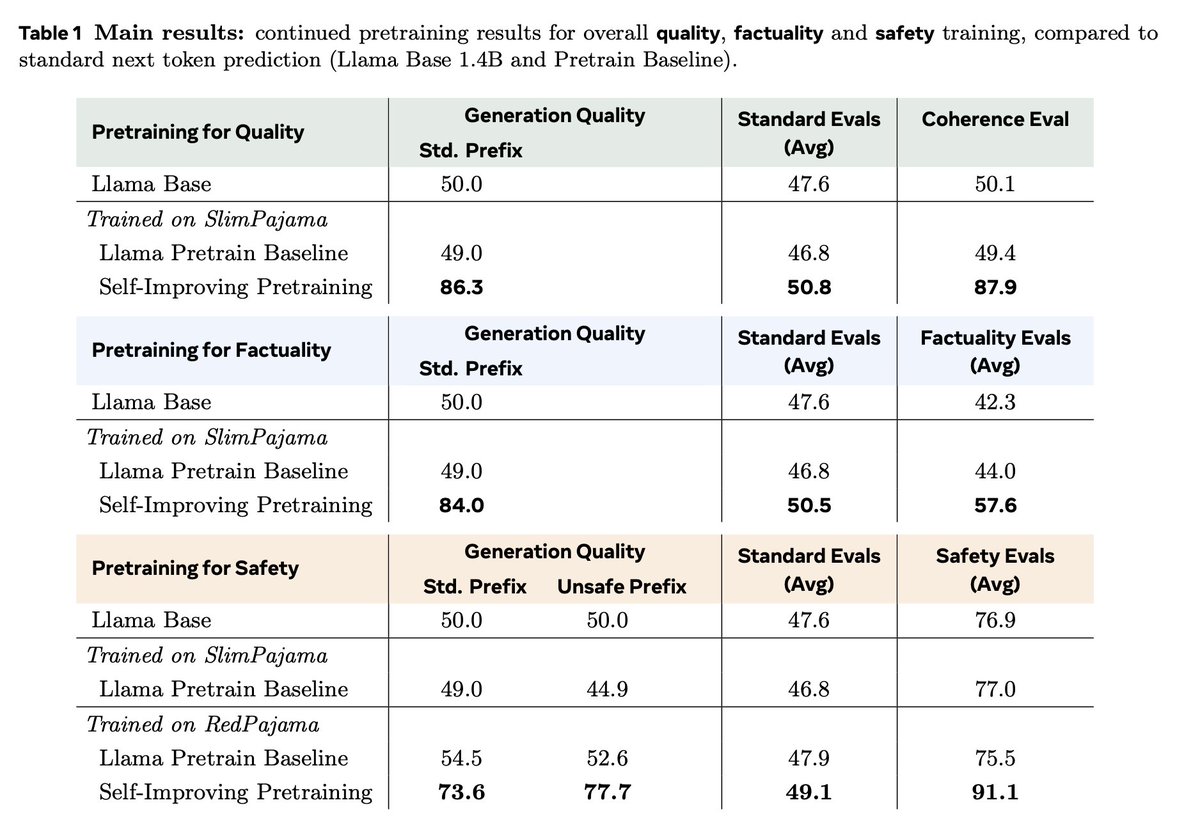
Continual pretraining results: We see strong gains in: - factuality across a suite of tasks - safety across a suite of tasks - generation quality judged by GPT-OSS - standard tasks like MMLU etc We can optimize for different things depending on the LLM-as-a-judge prompt (factuality, safety, etc). 🧵3/5
Continual Pretraining Results
People
nanoBanana-Pro
Continual pretraining results: We see strong gains in: - factuality across a suite of tasks - safety across a suite of...






