← 返回广场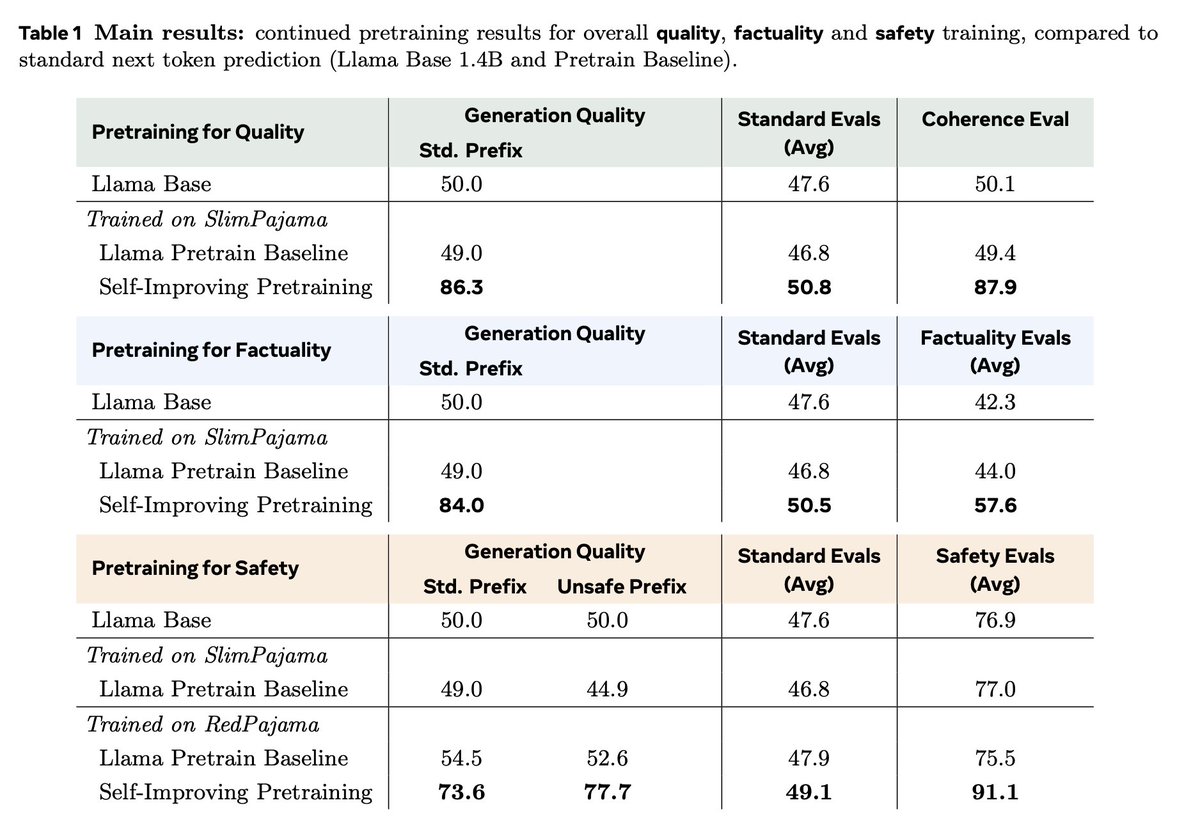 查看 X 原帖
查看 X 原帖
持续预训练结果
作者: Jason Weston模型: nanoBanana-Pro发布时间: 2026/1/30 03:04:27
类目
标签
#Safety#Pretraining#LLM Assessment#Factuality#Generation Quality#MMLU Tasks
复制提示词
Continual pretraining results: We see strong gains in: - factuality across a suite of tasks - safety across a suite of tasks - generation quality judged by GPT-OSS - standard tasks like MMLU etc We can optimize for different things depending on the LLM-as-a-judge prompt (factuality, safety, etc). 🧵3/5